RabbitMQ

RabbitMQ
YYT同步异步
同步:就是实时接收,比如视频聊天
异步:就是延迟接收,比如微信打字
为什么要选择MQ
1、便于拓展
主业务只需要将消息发送到消息队列中就行,其他业务按照自己的业务消费,比如订单支付成功后,发送消息到消息队列,其他业务:更新订单状态、发送短信、增加积分等等都可以解耦
2、提高性能
耗时:主业务+所有附加业务(更新订单状态、发送短信、增加积分等等)-> 主业务+发送消息
3、业务安全
如果主业务因为附加业务失败而失败,并不合理,比如用户下单成功,因为短信通知失败而给用户退款吗,有点意思。
利用MQ主业务不会因为受到附加业务的影响,比如短信未发送成功,不会影响用户已下单的状态
各类MQ对比
| 特性/产品 | RabbitMQ | Kafka | RocketMQ | ActiveMQ | Pulsar |
|---|---|---|---|---|---|
| 开发语言 | Erlang | Scala/Java | Java | Java | Java/C++ |
| 主要协议 | AMQP | 自定义协议 | 自定义协议 | JMS, AMQP, STOMP | Pulsar API |
| 吞吐量 | 万级/秒 | 十万~百万级/秒 | 十万级/秒 | 万级/秒 | 百万级/秒 |
| 延迟 | 微秒~毫秒级 | 毫秒级 | 毫秒级 | 毫秒级 | 5ms左右 |
| 可靠性 | 高(持久化+确认) | 高(副本机制) | 高(同步刷盘) | 中高 | 极高(分层存储) |
| 消息顺序 | 队列内有序 | 分区内有序 | 严格有序 | 队列内有序 | 分区内有序 |
| 消息堆积 | 一般(内存+磁盘) | 极强(磁盘存储) | 强(磁盘存储) | 一般 | 极强(分层存储) |
| 集群模式 | 镜像队列 | 分布式集群 | 主从+Dledger | 主从 | 分层架构(Broker+BookKeeper) |
| 部署复杂度 | 简单 | 中等 | 中等 | 简单 | 复杂 |
| 管理界面 | 优秀(内置) | 一般(第三方) | 良好(控制台) | 一般 | 良好 |
| 事务支持 | 有限支持 | 0.11+支持 | 完善支持 | 支持 | 支持 |
RabbitMQ
结构
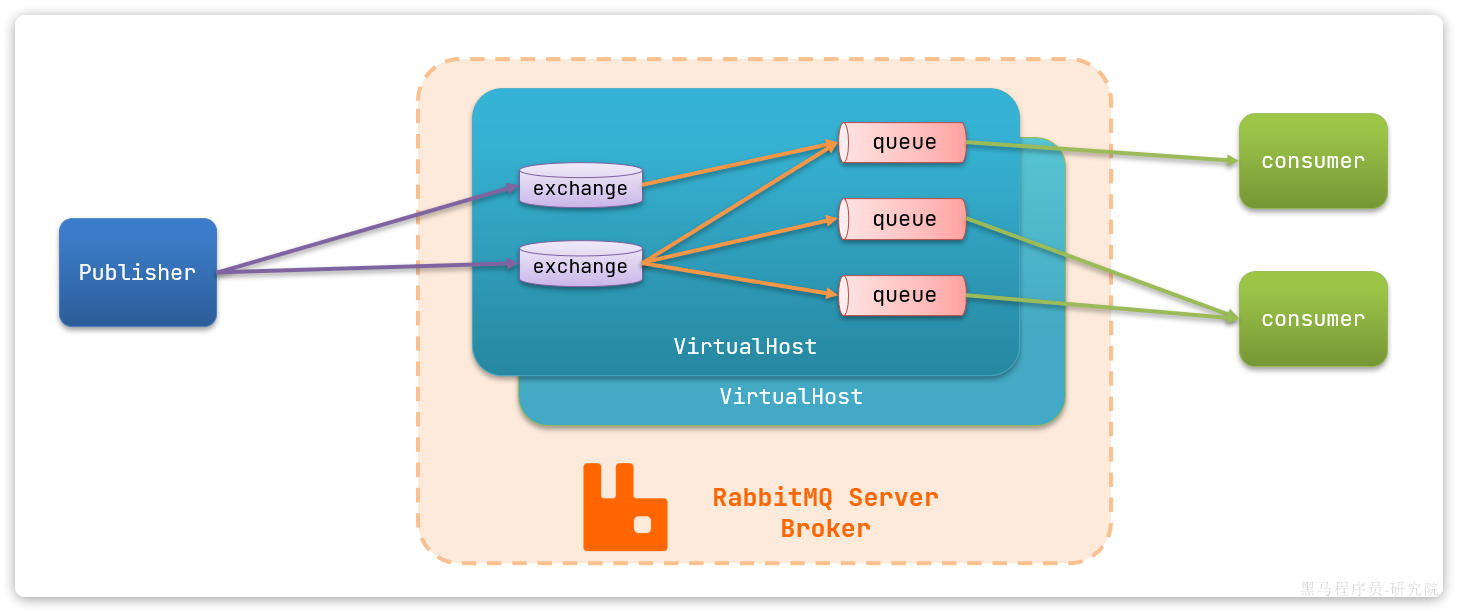
publisher:生产者,也就是发送消息的一方consumer:消费者,也就是消费消息的一方queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
WorkQueues
基本概念
- 定义:工作队列(Work Queue)模式也称为任务队列(Task Queue),用于将耗时任务分发给多个工作者(消费者)处理
- 核心特点:
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 消息在队列中按FIFO(先进先出)原则排队
- 适用于任务解耦和负载均衡
消息分发机制
- 轮询分发(Round-Robin):
- 默认分发策略,不管消费者处理能力,平均分配消息
- 问题:当消费者处理能力不同时,可能导致部分消费者过载
- 公平分发(Fair Dispatch):
- 通过
basicQos(prefetchCount)设置预取数量 - Broker只会在消费者空闲时推送新消息
- 保证处理能力强的消费者获得更多消息
- 通过
交换机类型
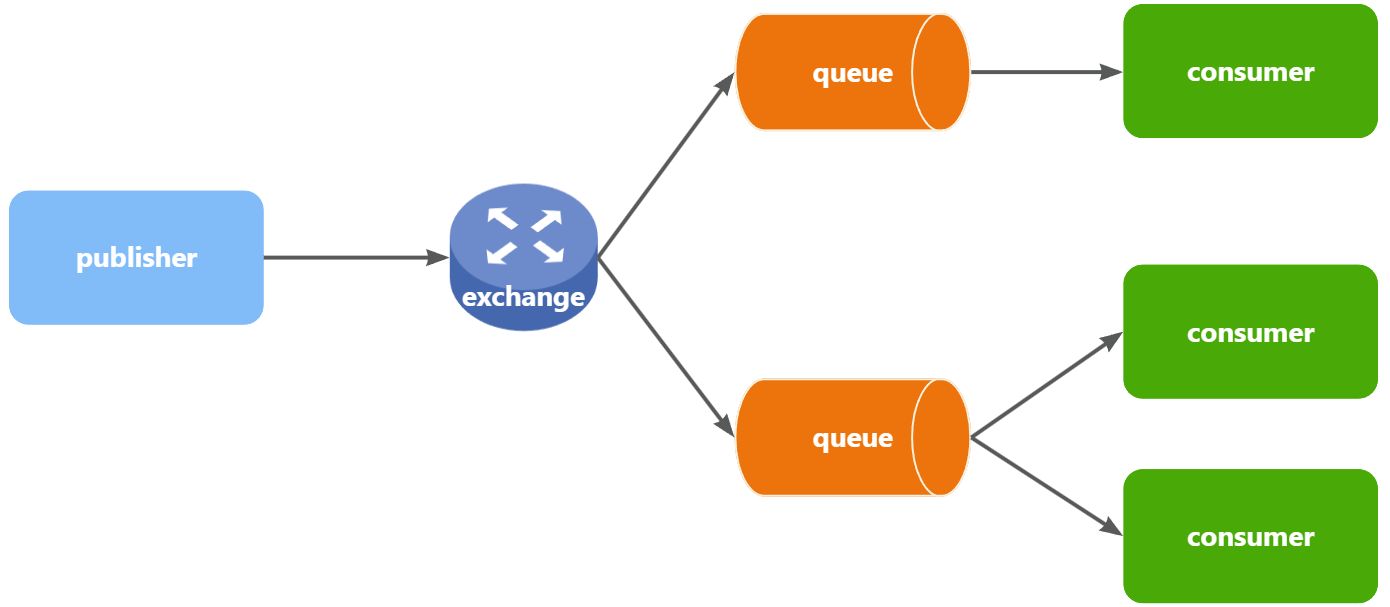
基本概念
- Publisher:生产者,不再发送消息到队列中,而是发给交换机
- Exchange:交换机,一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
- Queue:消息队列也与以前一样,接收消息、缓存消息。不过队列一定要与交换机绑定。
- Consumer:消费者,与以前一样,订阅队列,没有变化
重要特性:Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
交换机类型概览
| 类型 | 路由方式 | 适用场景 | 特点 |
|---|---|---|---|
| Fanout | 广播到所有绑定队列 | 事件通知、广播消息 | 忽略routing key |
| Direct | 精确匹配routing key | 点对点通信、任务路由 | 严格匹配 |
| Topic | 模式匹配routing key | 多维度消息分类 | 支持通配符 |
| Headers | 匹配消息headers属性 | 复杂路由条件 | 不依赖routing key |
1、Fanout(扇出交换机)
工作原理:
- 广播模式,将消息发送到所有与当前交换机绑定的队列
- 完全忽略routing key,即使指定了也不生效
- 适合”发布/订阅”模型
2、Direct(直连交换机)
工作原理:
- 交换机与队列绑定时,必须指定RoutingKey
- 消息发送时指定RoutingKey,只有完全匹配的队列才能收到消息
- 允许多个队列使用相同的RoutingKey(类似Fanout效果)
3、Topic(主题交换机)
工作原理:
- 与Direct类似,但支持RoutingKey通配符匹配
- BindingKey和RoutingKey都由单词组成,以
.分隔
通配符规则:
#:匹配0个或多个单词(多级匹配)*:匹配恰好1个单词(单级匹配)
匹配示例:
| Binding Key | Routing Key: item.spu.insert |
Routing Key: item.spu |
Routing Key: log.error.service |
|---|---|---|---|
item.# |
✓ 匹配 | ✓ 匹配 | ✗ 不匹配 |
item.* |
✗ 不匹配 | ✓ 匹配 | ✗ 不匹配 |
#.error.# |
✗ 不匹配 | ✗ 不匹配 | ✓ 匹配 |
*.*.insert |
✓ 匹配 | ✗ 不匹配 | ✗ 不匹配 |
4、Headers(头交换机)
工作原理:
- 不依赖RoutingKey,而是根据消息headers属性匹配
- 队列绑定时设置header匹配条件(键值对)
- 支持两种匹配模式:
x-match=all:所有header必须匹配(默认)x-match=any:任意一个header匹配即可
交换机属性
所有交换机类型都支持以下属性配置:
1 | channel.exchangeDeclare( |
| 属性 | 说明 | 建议值 |
|---|---|---|
| durable | 交换机是否持久化 | 生产环境设为true |
| autoDelete | 无绑定时是否自动删除 | 临时交换机设为true |
| internal | 是否仅内部使用(客户端无法发布) | 通常false |
| arguments | 扩展参数(如HA策略) | 按需设置 |
选择指南
- 需要广播消息 → 选择 Fanout
- 简单精确路由 → 选择 Direct
- 需要通配符或多维度路由 → 选择 Topic
- 基于消息头的复杂匹配 → 考虑 Headers(优先评估Topic替代方案)
- 不确定时 → 从 Direct 开始,根据需求演进
80%的场景使用Direct和Topic交换机即可满足需求,Fanout用于广播场景,Headers仅在特殊需求时使用。
可靠性保证
在分布式系统中,消息从生产者→MQ→消费者的过程中,每个环节都可能出现故障。RabbitMQ提供了多种机制确保消息可靠性传输,下面详细分析三个关键环节的保障方案。
1、生产者可靠
1.1 重试机制
触发条件:网络闪断、连接超时、MQ节点不可用
配置示例(Spring Boot):
1
2
3
4
5
6
7
8
9
10spring:
rabbitmq:
publisher-confirm-type: correlated
publisher-returns: true
template:
retry:
enabled: true
max-attempts: 3 # 最大重试次数
initial-interval: 1000ms # 初始重试间隔
multiplier: 2.0 # 间隔倍增系数最佳实践:
- 仅对幂等操作启用重试
- 重试间隔采用指数退避策略
- 重试失败后记录日志并告警
1.2 确认机制
Publisher Confirm
原理:MQ收到消息后异步返回ACK/NACK
三种模式:
模式 说明 适用场景 NONE 无确认 测试环境/非关键业务 SIMPLE 同步等待确认 低吞吐量关键业务 CORRELATED 异步回调确认 高吞吐量生产环境 工作流程:
1
2
3
4
5
6
7
8
9
10// 开启发布确认
channel.confirmSelect();
// 发布消息
channel.basicPublish(exchange, routingKey, props, message.getBytes());
// 等待确认(同步)
if (channel.waitForConfirms(5000)) {
System.out.println("Message confirmed");
}
Publisher Return
触发条件:消息成功送达MQ但路由失败
处理方式:
1
2
3
4
5// 设置Return回调
rabbitTemplate.setReturnsCallback(returned -> {
log.error("Message returned: {}", returned);
// 保存到数据库或发送告警
});
持久化消息确认时机
| 消息类型 | 确认时机 | 可靠性 |
|---|---|---|
| 临时消息 | 入队成功 | ★★☆ |
| 持久消息 | 入队+刷盘完成 | ★★★ |
Confirm和Return是互补机制,应同时启用。Confirm保证MQ收到消息,Return保证消息正确路由。
2、MQ可靠
2.1 持久化三要素
| 组件 | 持久化配置 | 重要性 |
|---|---|---|
| 交换机 | durable=true |
必须,否则重启后路由规则丢失 |
| 队列 | durable=true |
必须,否则重启后队列消失 |
| 消息 | deliveryMode=2 |
关键业务必须设置 |
声明示例:
1
2
3
4
5
6
7
8
9
10
11// 交换机持久化
channel.exchangeDeclare("exchange_name", "direct", true);
// 队列持久化
channel.queueDeclare("queue_name", true, false, false, null);
// 消息持久化
AMQP.BasicProperties props = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // 2=持久化
.build();
channel.basicPublish("exchange", "routing.key", props, message.getBytes());
2.2 Lazy Queue
工作原理:
- 消息直接写入磁盘,内存仅保留索引
- 消费时按需加载到内存(预读机制)
- 支持亿级消息堆积
启用方式:
1
2
3
4// 声明惰性队列
Map<String, Object> args = new HashMap<>();
args.put("x-queue-mode", "lazy");
channel.queueDeclare("lazy_queue", true, false, false, args);性能对比:
指标 普通队列 Lazy Queue 内存占用 高(100万条消息≈1GB) 低(仅索引) 写入速度 快 稍慢(磁盘IO) 读取速度 快 首次慢(需加载) 重启恢复 慢(需重放) 快(直接读磁盘) 适用场景:
- 长时间离线消费者
- 预期消息大量积压
- 内存资源受限的环境
Lazy Queue不替代消费者异常处理!应配合监控告警及时发现积压问题。
3、消费者可靠
3.1 消费者确认模式
| 模式 | 处理方式 | 适用场景 | 风险 |
|---|---|---|---|
| none | 立即ACK | 非关键业务/调试 | 消息丢失风险高 |
| manual | 业务代码手动ACK | 关键业务/复杂处理 | 开发复杂度高 |
| auto | 异常时NACK/REJECT | 大多数业务场景 | 需正确处理异常 |
Spring Boot配置:
1
2
3
4
5spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual # 或auto/none
3.2 失败重试策略
本地重试(推荐):
1
2
3
4
5
6
7
8spring:
rabbitmq:
listener:
simple:
retry:
enabled: true
max-attempts: 3
initial-interval: 1000ms- 优点:避免无效队列积压,减少网络开销
- 缺点:重试期间线程阻塞
重试耗尽处理:
策略 行为 适用场景 RejectAndDontRequeueRecoverer 丢弃消息 可容忍丢失的日志类消息 ImmediateRequeueMessageRecoverer 重新入队 临时性故障(如DB连接超时) RepublishMessageRecoverer 转发到死信队列 关键业务,需人工干预
3.3 幂等性保障
唯一ID方案
1 | // 1. 生产者生成唯一ID |
业务状态校验
1 | // 更新订单状态时校验 |
3.4 兜底方案
定时对账:
1
2
3
4
5
6
7
8
9
public void reconciliation() {
List<Order> pendingOrders = orderService.findPendingMoreThan(30min);
for (Order order : pendingOrders) {
if (paymentService.checkPaid(order.getId())) {
orderService.confirmPayment(order.getId());
}
}
}人工干预通道:
- 死信队列监控仪表盘
- 消息重发管理界面
- 失败消息分类统计
延迟消息
1. TTL+死信队列实现
架构:
1 | 生产者 → 普通交换机 → TTL队列(无消费者) |
配置步骤:
1 | // 1. 声明死信交换机 |
2. RabbitMQ延迟插件
优势:原生支持延迟消息,无需死信队列
安装:
1
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
使用:
1
2
3
4
5
6
7
8
9
10// 声明延迟交换机
Map<String, Object> args = new HashMap<>();
args.put("x-delayed-type", "direct");
channel.exchangeDeclare("delay.exchange", "x-delayed-message", true, false, args);
// 发布延迟消息
AMQP.BasicProperties props = new AMQP.BasicProperties.Builder()
.headers(Collections.singletonMap("x-delay", 5000)) // 5秒延迟
.build();
channel.basicPublish("delay.exchange", "routing.key", props, message.getBytes());
3. 方案对比
| 方案 | 精确度 | 吞吐量 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| TTL+DLX | 低(队列级TTL) | 中 | 高 | 简单延迟需求 |
| 延迟插件 | 高(消息级延迟) | 高 | 低 | 精确延迟场景 |
| 外部调度器 | 极高 | 低 | 极高 | 超长延迟(小时级+) |
最佳实践:30分钟内的延迟用TTL+DLX,精确到秒级的用延迟插件,超长延迟考虑时间轮算法+数据库存储。
全链路可靠性保障方案
1 | graph LR |
核心原则:
- 生产端:确保消息必达MQ
- MQ端:确保消息不丢失
- 消费端:确保消息必处理且只处理一次
- 兜底:建立最终一致性补偿机制
没有100%可靠的系统,只有可接受的失败概率。根据业务容忍度设计合理的可靠性方案,避免过度设计。






