JUC

JUC
YYTJava内存模型(JMM)详解
Java内存模型(JMM) 是一套规范,定义了多线程环境下线程如何访问共享变量的规则,主要解决三大核心问题:可见性、原子性和有序性。
1. 可见性
每个线程拥有自己的工作内存(缓存),存储主内存中共享变量的副本。当线程A修改了共享变量后,若不采取特殊措施,线程B可能无法立即看到这个修改,仍使用旧值。
解决方案:
- volatile关键字:确保变量的修改立即同步到主内存,并使其他线程中该变量的缓存失效,强制重新从主内存读取最新值
- synchronized/ReentrantLock:解锁前会将修改刷新至主内存
- final关键字:保证final字段的初始化在构造函数完成后对其他线程可见
2. 原子性
复合操作(如i++)包含”读取-修改-写入”三个步骤,多线程环境下可能导致操作交错,使结果不符合预期。
示例:当i=10时,两个线程同时执行i++,理想结果应为12,但实际可能只增加1次变为11,因为:
- 线程A读取i=10
- 线程B也读取i=10
- 线程A将i增加为11并写回
- 线程B将i增加为11(基于旧值10)并写回
解决方案:
- synchronized/ReentrantLock:保证同一时刻只有一个线程执行临界区代码
- 原子类(AtomicInteger等):基于CAS(Compare-And-Swap)实现无锁原子操作
- volatile:仅保证单个变量的读/写原子性,不适用于复合操作
3. 有序性
编译器和处理器可能会对指令进行重排序优化,导致代码执行顺序与编写顺序不一致。
示例:对象初始化过程
1 | // 可能发生指令重排 |
解决方案:
- volatile:插入内存屏障(Memory Barrier),禁止特定类型的指令重排序
- synchronized/ReentrantLock:保证同步块内的代码执行具有顺序性
- happens-before原则:JMM定义的一组天然的顺序保证规则,如程序顺序规则、锁规则、volatile变量规则等
Java线程创建的四种方式
1. 继承Thread类
1 | public class MyThread extends Thread { |
工作原理:通过继承Thread类并重写其run()方法,定义线程执行的任务。调用start()方法启动线程,JVM会自动调用run()方法。
优点:
- 实现简单直观
缺点:
- 线程类已经继承了Thread类,所以不能再继承其他的父类
2. 实现Runnable接口
1 | public class MyRunnable implements Runnable { |
工作原理:实现Runnable接口的run()方法定义任务,将任务实例传给Thread对象,由线程执行任务。
优点:
- 线程类只是实现了Runable接口,还可以继承其他的类
缺点:
- 无法直接获取线程执行结果
3. 实现Callable接口与FutureTask
1 | import java.util.concurrent.*; |
工作原理:实现Callable接口的call()方法定义有返回值的任务,配合FutureTask包装或提交给线程池执行。通过Future对象可以获取任务执行结果、检查执行状态或取消任务。
优点:
- 可以获取线程执行结果
缺点:
- 复杂
4. 使用线程池(Executor框架)
1 | import java.util.concurrent.*; |
工作原理:通过Executor框架提供的线程池实现,复用预先创建的线程来执行任务,避免频繁创建销毁线程的开销。
优点:
- 线程池可以重用预先创建的线程,避免了线程创建和销毁的开销,显著提高了程序的性能
缺点:
- 配置相对复杂
- 不当使用可能导致资源泄漏(忘记关闭线程池)
四种方式对比与选择建议
| 创建方式 | 获取返回值 | 异常处理 | 线程复用 | 适用场景 |
|---|---|---|---|---|
| 继承Thread | 不支持 | 有限 | 不支持 | 简单场景,学习用途 |
| 实现Runnable | 不支持 | 有限 | 不支持 | 任务与线程解耦,类已有父类 |
| Callable+Future | 支持 | 完善 | 部分支持 | 需要返回结果或完善异常处理 |
| 线程池 | 支持 | 完善 | 完全支持 | 生产环境,高并发应用 |
停止线程
什么是中断状态?
中断状态(interrupted status)是每个线程内部的一个布尔标志位,用来记录该线程是否被请求中断。
- 当调用
thread.interrupt()时,会设置这个标志位为true - 线程可以通过
Thread.isInterrupted()来检查自己的中断状态 - 或者通过
Thread.interrupted()来检查并清除中断状态
四种停止线程的方法详解
1. 异常法(推荐)
1 | public class InterruptExample { |
关键点:
- 调用
interrupt()设置中断标志 - 在
run()方法中定期检查isInterrupted() - 如果在
sleep()、wait()等阻塞方法中被中断,会抛出InterruptedException - 需要处理异常,并可能重新设置中断状态
2. 在沉睡中停止
1 | public class SleepInterruptExample { |
3. stop() 方法(不推荐)
1 | // 不推荐使用,因为会立即终止线程 |
为什么不推荐?
stop()会立即终止线程,不给线程任何清理机会- 可能导致对象处于不一致状态
- 可能造成资源泄漏(如文件未关闭、数据库连接未释放)
- 从Java 1.2开始已被标记为废弃(deprecated)
4. 使用 return 停止线程
1 | public class ReturnStopExample { |
总结
| 方法 | 是否推荐 | 特点 |
|---|---|---|
interrupt() + 检查中断状态 |
✅ 推荐 | 礼貌地请求中断,线程可以优雅退出 |
interrupt() + 处理 InterruptedException |
✅ 推荐 | 对于阻塞操作很有效 |
stop() |
❌ 不推荐 | 强制停止,可能导致资源泄漏 |
return 结合中断检查 |
✅ 推荐 | 简单直接,适合简单场景 |
线程状态
new->runnable->blocked->waiting->timed_waiting->terminated
sleep&wait
| 特性 | sleep() |
wait() |
|---|---|---|
| 所属类 | Thread 类(静态方法) | Object 类(实例方法) |
| 锁释放 | ❌ 不释放锁 | ✅ 释放锁 |
| 使用前提 | 任意位置调用,无需持有锁 | 必须在同步块内(持有锁) |
| 唤醒机制 | 超时自动恢复(时间到自动唤醒) | 需要 notify() 或 notifyAll() 唤醒,或超时 |
| 设计用途 | 暂停线程执行,不涉及锁协作 | 线程间协调,释放锁让其他线程工作 |
| 异常类型 | InterruptedException |
InterruptedException |
| 是否需要捕获异常 | 是 | 是 |
| 典型应用场景 | 定时任务、延时操作 | 生产者-消费者模式、线程等待条件满足 |
blocked和waiting
BLOCKED是锁竞争失败后被被动触发的状态,WAITING是人为的主动触发的状态
BLCKED的唤醒时自动触发的,而WAITING状态是必须要通过特定的方法来主动唤醒
线程间通信方式
1. 使用 volatile 关键字
工作原理
volatile关键字用于确保变量的更新对所有线程立即可见。- 它通过禁止指令重排序和保证内存可见性来实现线程间的简单通信。
1 | public class VolatileExample { |
2. 使用 Object 类的 wait()、notify() 和 notifyAll() 方法
工作原理
- 这些方法必须在同步块(synchronized block)内使用,以确保线程安全。
wait():使当前线程等待,同时释放锁,允许其他线程执行。notify():唤醒一个正在等待该对象监视器的单个线程。notifyAll():唤醒所有正在等待该对象监视器的线程。
1 | public class WaitNotifyExample { |
3. 使用 juc 包中的 Lock 和 ReentrantLock 结合 Condition 接口
工作原理
Lock提供了比同步块更灵活的锁定机制。Condition对象可以用来替代传统的wait()/notify()模式,提供了更加细粒度的控制。- 可以创建多个
Condition对象实现精准唤醒
- 可以创建多个
1 | import java.util.concurrent.locks.Condition; |
总结
| 方式 | 特点 | 适用场景 |
|---|---|---|
volatile |
简单高效,但仅限于单一变量的可见性 | 状态标志或轻量级同步 |
wait()/notify() |
需要在同步块中使用,支持线程间协作 | 生产者-消费者等需要线程协作的场景 |
Lock + Condition |
提供更灵活的锁定和通知机制 | 复杂的同步需求,特别是需要多个条件变量 |
synchronized 工作原理
synchronized是Java实现线程同步的核心机制,其工作原理主要基于JVM的Monitor监视器和锁升级策略。
从底层看,每个Java对象都有一个Monitor对象,当线程进入synchronized代码块时,会尝试获取这个Monitor的持有权。Monitor内部维护了持有线程ID、等待队列和条件队列等数据结构,确保同一时刻只有一个线程能执行同步代码。
从性能优化角度看,JDK 1.6之后synchronized实现了锁升级机制:从无锁状态开始,根据竞争情况依次升级为偏向锁、轻量级锁和重量级锁。偏向锁适用于单线程场景,直接记录线程ID避免CAS操作;轻量级锁适用于线程交替执行场景,通过CAS实现无阻塞同步;重量级锁则用于高竞争场景,依赖操作系统互斥量实现。
此外,synchronized不仅保证原子性,还通过内存屏障确保可见性:线程获取锁时会清空工作内存,释放锁时会将修改刷新到主内存,严格遵循happens-before原则。
ReentrantLock工作原理
1. 核心依赖:AQS框架
ReentrantLock的底层实现基于AbstractQueuedSynchronizer (AQS),这是一个提供了基本同步机制的框架,包含:
- 状态变量(state):表示锁的状态
- FIFO等待队列:存储等待获取锁的线程
2. 关键特性
可中断性
1 | lock.lockInterruptibly(); // 等待时可被中断 |
线程在等待锁的过程中可以被其他线程中断,从而提前结束等待。
支持超时时间
1 | lock.tryLock(1000, TimeUnit.MILLISECONDS); // 等待1秒后放弃 |
可以设置等待锁的超时时间,避免无限期等待。
公平锁与非公平锁
1 | // 非公平锁(默认) |
- 非公平锁:允许线程插队,吞吐量更高
- 公平锁:按申请顺序排队,避免线程饥饿
多个条件变量
1 | Condition condition = lock.newCondition(); |
支持创建多个条件变量,实现更精细的线程间通信。
可重入性
同一个线程可以多次获取同一把锁,不会造成死锁。通过内部的holdCount计数器实现:
- 获取锁时计数递增
- 释放锁时计数递减
- 只有当计数为0时,其他线程才有机会获取锁
AQS
AQS核心思想是,如果被请求的共享资源空闲,那么就将当前请求资源的线程设置为有效的工作线程,将共享资源设置为锁定状态;如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中。
组成部分
状态:state;(根据具体的实现类来使用,比如ReentrantLock,0表示无锁,1表示占有锁,大于1表示重入次数)
控制线程抢锁和配合的FIFO队列(双向链表);
期望协作工具类去实现的获取/释放等重要方法(重写)。
CAS
基本原理
CAS是硬件级别的原子操作,包含三个操作数:
- V:内存位置
- A:预期原值
- B:新值
操作逻辑:当且仅当V==A时,将V更新为B,整个过程原子执行。
问题
- ABA问题:值从A→B→A变化时CAS无法感知。解决方案:
- 版本号
- 标记是否修改
- 自旋开销:高并发下频繁重试消耗CPU。解决方案:
- 设定自旋次数:根据历史成功率动态调整
- 指数退避:每次失败后等待时间指数级增长
- 混合策略:短时间自旋 + 长时间阻塞
- 单变量限制:只能保证一个变量的原子性。解决方案:
- 将多个变量封装为对象
悲观锁&乐观锁
悲观锁
核心思想
“总是假设最坏情况” — 认为并发冲突必然发生,因此在访问共享资源前主动加锁,确保同一时刻只有一个线程能操作资源。
乐观锁
核心思想
“总是假设最好情况” — 认为并发冲突不常发生,不主动加锁,只在提交更新时检查是否有冲突,冲突时采取补偿措施。
实现方法
1、CAS:基础操作,通过原子比较并交换实现无锁更新,如AtomicInteger等原子类。
2、版本号:增加版本字段,更新时比对版本号,仅当版本一致时更新成功,避免覆盖冲突。
3、时间戳:记录数据更新时间,更新前比对时间戳,若当前时间大于数据时间戳则说明已被修改,更新失败。
voliatle
volatile关键字在Java中主要有两个核心作用:
保证可见性
当一个变量被声明为volatile时,对它的写操作会立即刷新到主内存,读操作则直接从主内存读取。这确保了多线程环境下,一个线程对volatile变量的修改能被其他线程立刻看到,避免因工作内存缓存导致的不可见问题。禁止指令重排序优化
volatile通过插入内存屏障(Memory Barrier)来防止编译器和处理器对指令进行重排序,具体包括:- 写-写(Write-Write)屏障:在对
volatile变量写入前,插入写屏障,确保其之前的所有普通写操作已完成。 - 读-写(Read-Write)屏障:在对
volatile变量读取后,插入读屏障,确保其之后的所有普通写操作不会被提前执行。 - 写-读(Write-Read)屏障:这是最关键的一类,它确保
volatile写操作之前的所有内存操作不会被重排到写操作之后,且volatile读操作之后的所有内存操作不会被重排到读操作之前。
- 写-写(Write-Write)屏障:在对
什么情况下会产生死锁?如何解决?
一、死锁产生的四个必要条件(同时满足)
互斥条件
资源一次只能被一个线程使用,不能共享。持有并等待条件
线程已持有一个资源,又申请另一个被占用的资源,但不释放已持有的资源。不可剥夺条件
已获得的资源在使用完之前不能被强制剥夺,必须由持有者主动释放。环路等待条件
多个线程之间形成循环等待关系,如:A等B的资源,B等C的资源,C等A的资源。
只有当这四个条件同时成立时,才会发生死锁。
二、预防与解决方法
| 方法 | 原理 | 示例 |
|---|---|---|
| 破坏互斥条件 | 尽量使用可共享资源,避免独占 | 使用ConcurrentHashMap替代同步集合 |
| 破坏持有并等待 | 要求线程一次性申请所有资源,或先释放再申请 | ReentrantLock使用tryLock()实现超时获取 |
| 破坏不可剥夺条件 | 允许抢占资源,或设置超时机制 | 使用lock.tryLock(timeout) |
| 破坏环路等待条件 | 对资源统一编号,按序申请 | 所有线程按资源ID从小到大申请 |
线程池
工作原理
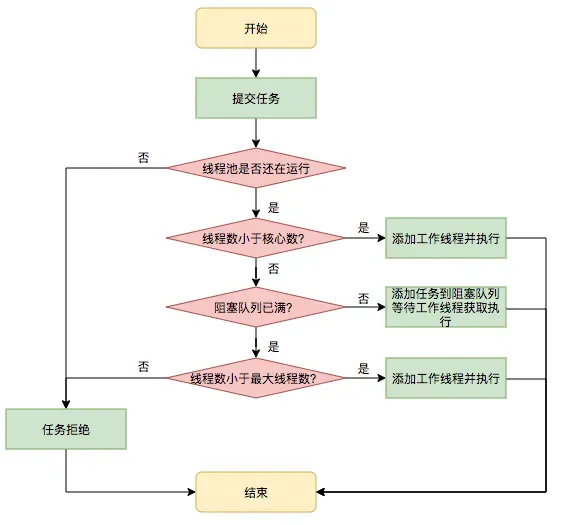
线程池执行流程:
- 当提交新任务时,首先判断当前线程数是否小于核心线程数
- 是:创建新核心线程执行任务
- 否:进入下一步
- 判断任务队列是否已满
- 否:将任务放入任务队列
- 是:进入下一步
- 判断当前线程数是否小于最大线程数
- 是:创建非核心线程执行任务
- 否:执行拒绝策略
七大核心参数
1. corePoolSize(核心线程数)
- 定义:线程池中保持的最小线程数,即使空闲也不会被回收(除非设置allowCoreThreadTimeOut)
- 设置建议:
- CPU密集型任务:Ncpu + 1
- IO密集型任务:Ncpu * 2
- 特点:默认情况下,核心线程仅在有任务到达时才创建,可通过prestartAllCoreThreads()预先创建
2. maximumPoolSize(最大线程数)
- 定义:线程池允许创建的最大线程数
- 设置建议:
- 受限于系统资源,特别是内存
- 通常为:
(线程等待时间/线程CPU时间 + 1) × CPU核心数
- 注意:当队列是无界队列时,此参数无效(因为任务不会排队等待,而是直接入队)
3. keepAliveTime(空闲线程存活时间)
- 定义:非核心线程空闲时的最长存活时间
- 单位:由TimeUnit参数指定
- 扩展:从Java 1.6开始,可通过allowCoreThreadTimeOut(true)使此参数也适用于核心线程
4. unit(时间单位)
- 定义:keepAliveTime的时间单位
- 常用单位:
- TimeUnit.MILLISECONDS(毫秒)
- TimeUnit.SECONDS(秒)
- TimeUnit.MINUTES(分钟)
- 示例:
TimeUnit.SECONDS表示keepAliveTime以秒为单位
5. workQueue(任务队列)
- 定义:用于保存等待执行任务的阻塞队列
- 常见类型:
- ArrayBlockingQueue:有界队列,基于数组结构
- LinkedBlockingQueue:可设置容量的队列,基于链表结构
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作必须等待另一个线程的移除操作
- PriorityBlockingQueue:具有优先级的无限阻塞队列
- 选择策略:
- 任务数量固定:使用有界队列
- 任务数量波动大:使用SynchronousQueue
- 任务有优先级:使用PriorityBlockingQueue
6. threadFactory(线程工厂)
定义:用于创建新线程的工厂类
默认实现:Executors.defaultThreadFactory()
自定义用途:
- 设置线程名称(便于问题排查)
- 设置线程优先级
- 设置守护线程
- 捕获异常
示例:
1
2
3
4
5
6
7
8
9
10
11new ThreadFactory() {
private final AtomicInteger threadNumber = new AtomicInteger(1);
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, "CustomPool-" + threadNumber.getAndIncrement());
thread.setDaemon(false);
thread.setPriority(Thread.NORM_PRIORITY);
return thread;
}
}
7. handler(拒绝策略)
- 定义:当任务无法被线程池执行时的处理策略
- 内置策略:
- AbortPolicy(默认):直接抛出RejectedExecutionException异常
- CallerRunsPolicy:由调用线程(提交任务的线程)执行该任务
- DiscardPolicy:静默丢弃任务,不抛异常
- DiscardOldestPolicy:丢弃队列中最旧的任务,然后重新尝试提交
- 自定义策略:实现RejectedExecutionHandler接口
- 适用场景:
- AbortPolicy:适用于关键任务,不允许丢失
- CallerRunsPolicy:适用于任务可由调用方线程处理的场景
- DiscardPolicy:适用于允许任务丢失的场景
- DiscardOldestPolicy:适用于保留最新任务的场景
实际应用示例
1 | // 创建自定义线程池 |
最佳实践
避免使用Executors创建线程池:
- FixedThreadPool和SingleThreadPool:使用无界队列,可能导致OOM
- CachedThreadPool:最大线程数为Integer.MAX_VALUE,可能导致创建过多线程
合理设置队列容量:
- 有界队列可防止资源耗尽
- 根据系统负载和任务特性选择合适的容量
监控线程池状态:
- 使用beforeExecute/afterExecute钩子方法
- 监控队列大小、活跃线程数等指标
优雅关闭:
1
2
3
4
5
6
7
8executor.shutdown(); // 停止接收新任务
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow(); // 强制关闭
}
} catch (InterruptedException e) {
executor.shutdownNow();
}






